一、现象
无论哪个JDK实现 HashMap,都不是线程安全。但开发者水平有限,使用 JDK7 HashMap 在多线程操作,或者别人在无意识下把含有 HashMap 的方法在多线程中调用,都将导致不可预测的问题。
由于服务端多线程并发的原因,调用 HashMap.get(K key) 的时候,会偶发处理器100%占用现象。
除了在服务端,Android 开发也偶尔需要 Map 上的多线程操作。因为移动端开发人员水平参差不齐,并不知道使用 ConcurrentHashMap 或其他线程保护,所以出现这个问题的状况也不罕见。
二、起因
上述两者 HashMap 死循环的场景,正出现在多线程同时插入新元素的过程。
为了缓解这个问题,JDK8 对 HashMap 进行调整,优化 HashMap 在多线程出现死循环的场景,把元素迁移的头插法改为尾插法。
不过,该类依然不是线程安全,且需要遍历桶内所有节点才能插入新元素,引入开销。
三、源码实现
下面先看JDK7基本代码,这是插入新元素的公开方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
// 获取键的哈希值
int hash = hash(key.hashCode());
// 计算键哈希值对应桶
int i = indexFor(hash, table.length);
// 开始从选定哈希桶查找目标元素
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 如果该键对应值已存在,则替换并返回该旧值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 键不存在则创建新的节点
addEntry(hash, key, value, i);
return null;
}
创建新节点,从以下源码可知是链表的头插法
1
2
3
4
5
6
7
8
9
10
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取已有链表头节点
Entry<K,V> e = table[bucketIndex];
// 创建新节点,并把上述链表头结点作为后续元素
// 然后自己作为该哈希表的头节点
table[bucketIndex] = new Entry<>(hash, key, value, e);
// 由于元素数量超过阈值,所以触发扩容
if (size++ >= threshold)
resize(2 * table.length);
}
开始扩容操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新哈希表已经创建
Entry[] newTable = new Entry[newCapacity];
// 旧哈希桶表元素迁移到新哈希表
transfer(newTable);
// 新哈希表替换旧表
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
迁移元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
void transfer(Entry[] newTable) {
// src代表旧哈希表数组
Entry[] src = table;
int newCapacity = newTable.length;
// 遍历旧哈希表逐个迁移表内元素
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
// 此代码块内是从旧哈希表元素迁移到新哈希表操作
Entry<K,V> next = e.next;
// 在新哈希表选择对应
int i = indexFor(e.hash, newCapacity);
// 下面3行代码就是链表头插法操作
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
四、图解流程
为了方便描述,基本条件假设为:
- 原哈希表桶数量4、负载因子0.75、扩容阈值3、只有 元素c;
- 线程2 把 元素b 头插入旧哈希表,线程1 把 元素a 头插入旧哈希表;
- 上述3个元素的哈希值,假设无论重哈希前还是之后,都会运算到同一个桶;
- 插入完成后旧哈希表 桶索引为3 元素顺序为 元素a->元素b->元素c;
- 两个线程根据系统调度,分别检查扩容阈值并各自触发扩容操作;
由于只用文字表述比较晦涩,所以加入下面图解有助理解。
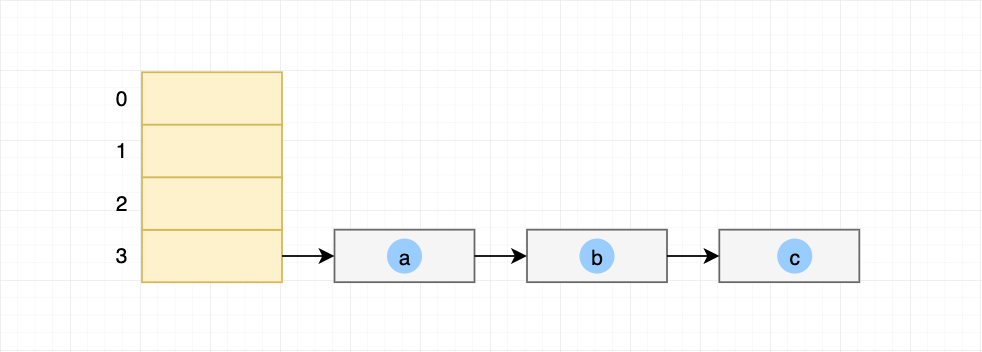
两个线程插入完成后旧哈希表,在桶索引为3的元素顺序为 元素a->元素b->元素c
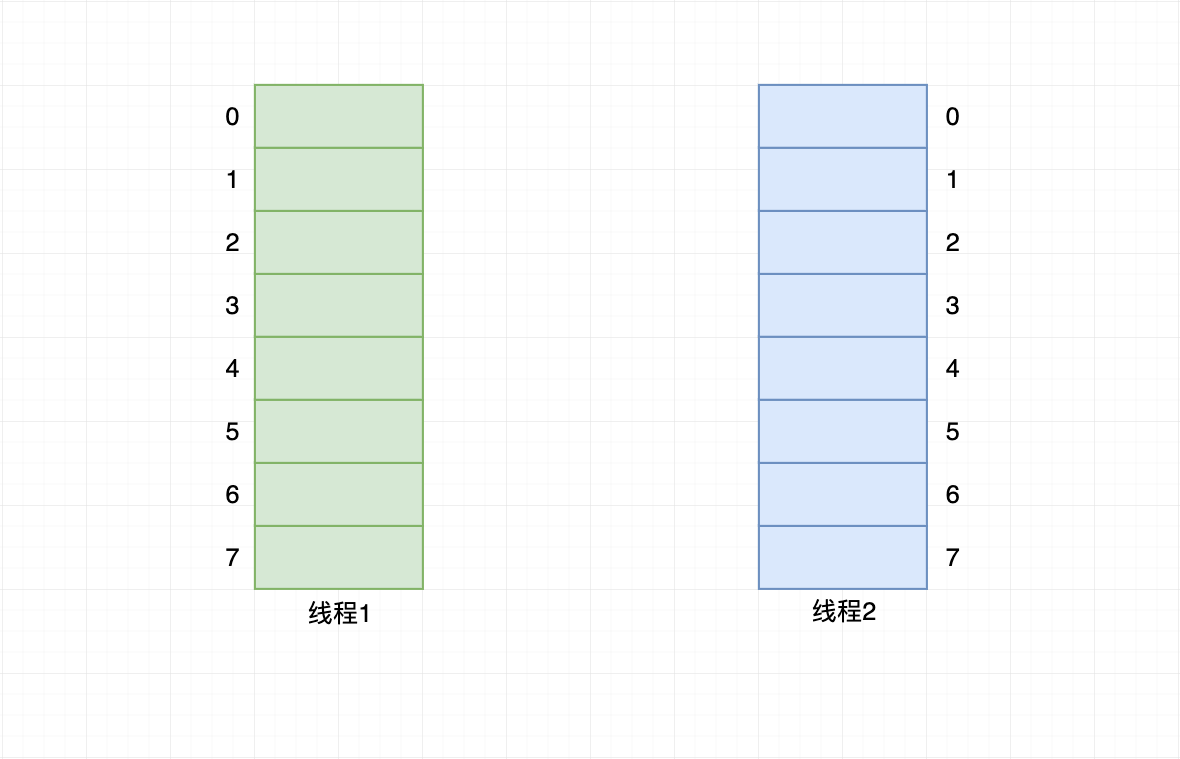
两个线程写入哈希表后达到阈值后,各自开始扩容操作并创建新哈希桶。
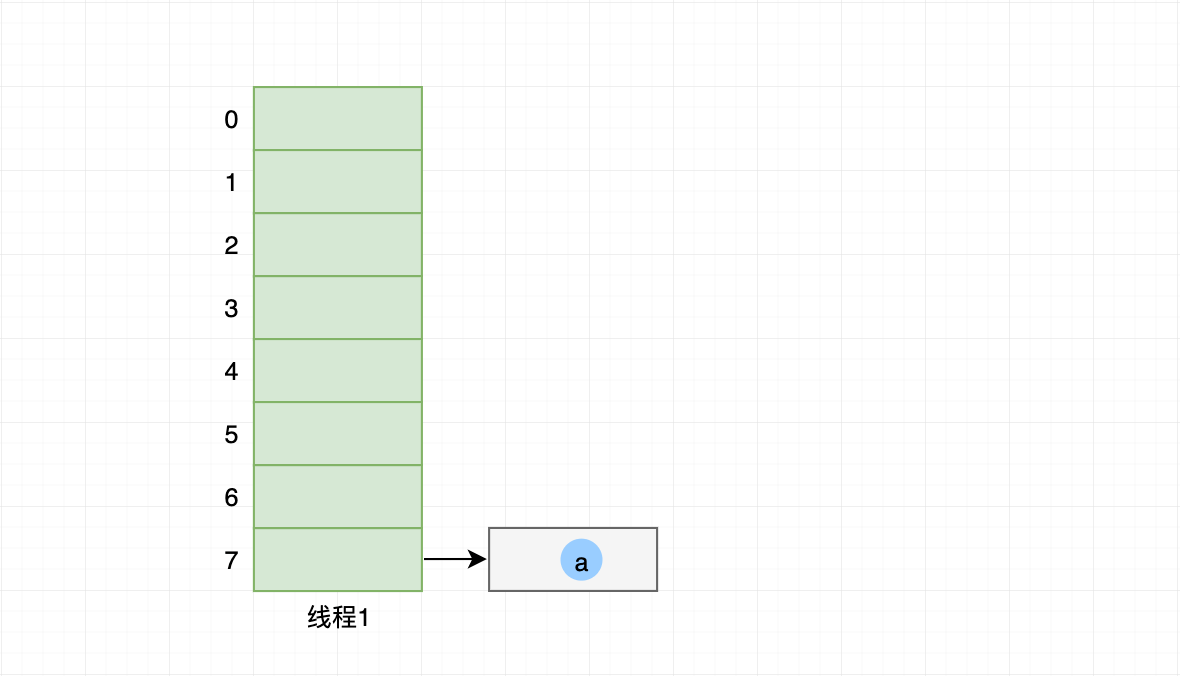
线程2 进入 transfer(Entry[] newTable):
- 迁移元素到新哈希桶,操作执行到注释所在位置,处理器时间片用完被暂停;
- 此时对 线程2 来说,引用e 指向 元素a,引用e.next 指向 元素b;
- 时间片分配给 线程1 并继续执行;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
// 线程2首次进入循环且上述代码已执行完成,暂停在此位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
线程1 也开始以上操作,并把旧哈希桶的 元素a 通过头插法,插入到 线程1 创建的新哈希桶内:
线程1 迁移 元素b 到自己的哈希桶内:
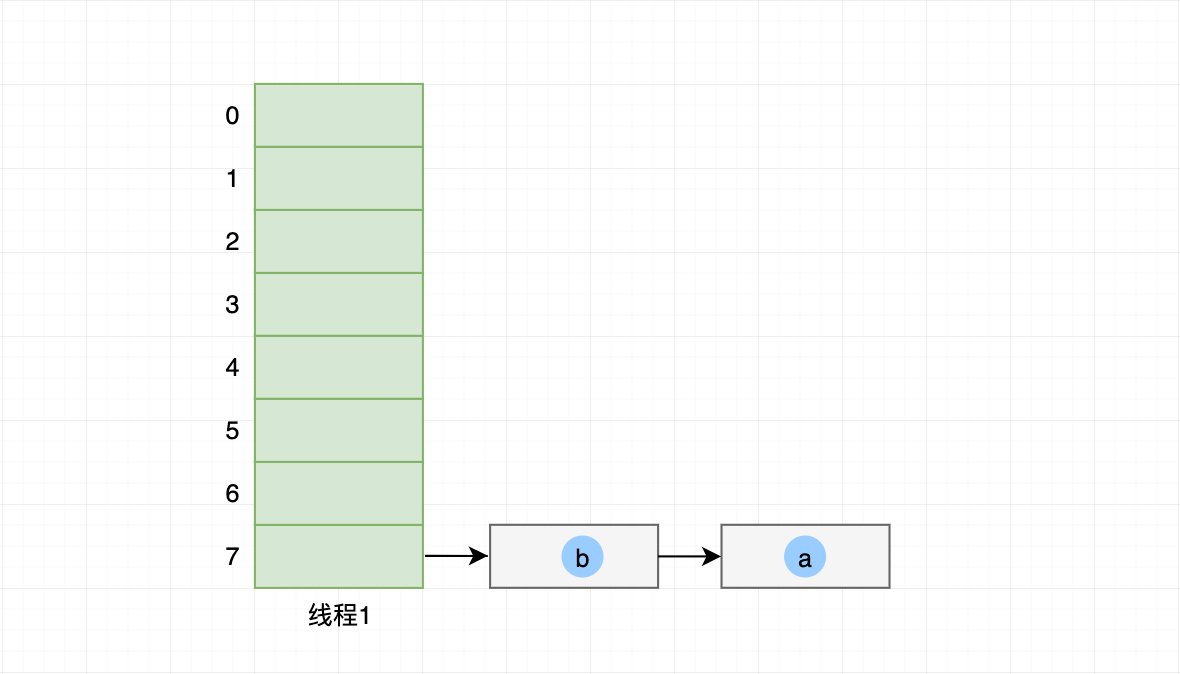
线程1 头插法迁移 元素c 到哈希桶内,最终 线程1 哈希桶索引7链表顺序为 c->b->a。
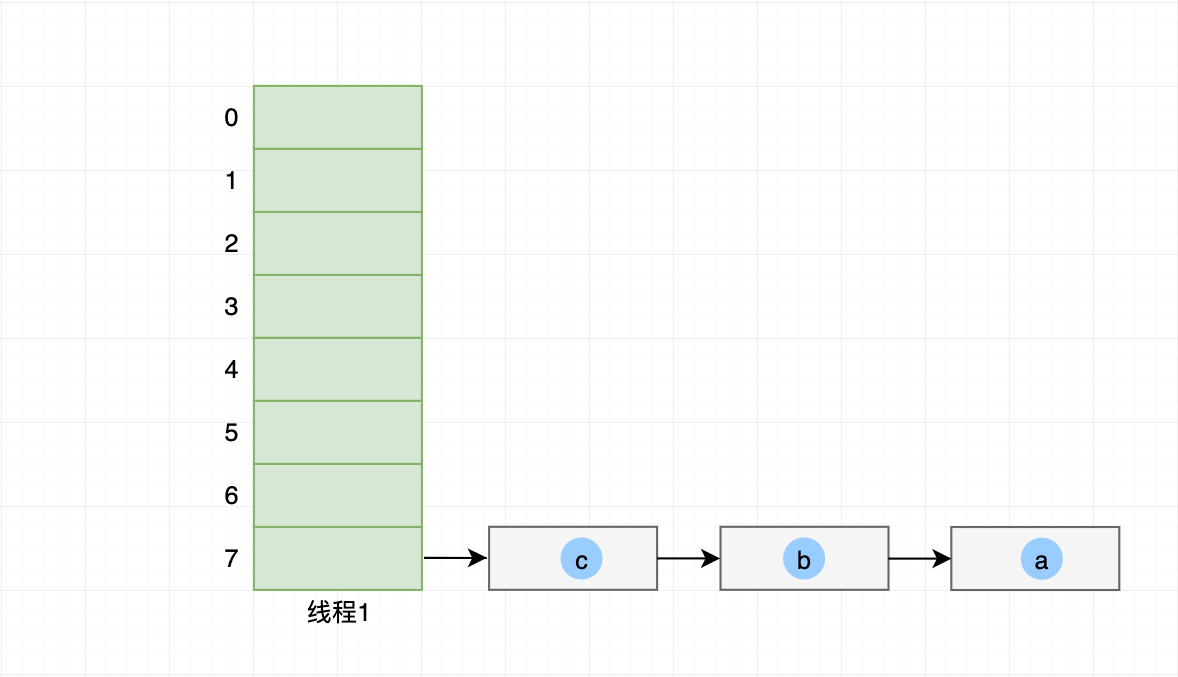
这个时候,线程1 处理器时间片用完停在以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
// 线程1把所有元素迁移到自己创建的新哈希表内
transfer(newTable);
// 时间片耗尽,上述代码执行完毕暂停在此
// 新哈希表还没替换旧哈希表
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
线程2 操作恢复,如下图所示:
- 对 线程2 来说,不知道 线程1 已经改变以下元素的链表顺序;
- 只知道自己的 引用e 依然指向 元素a,e.next 指向 元素b;
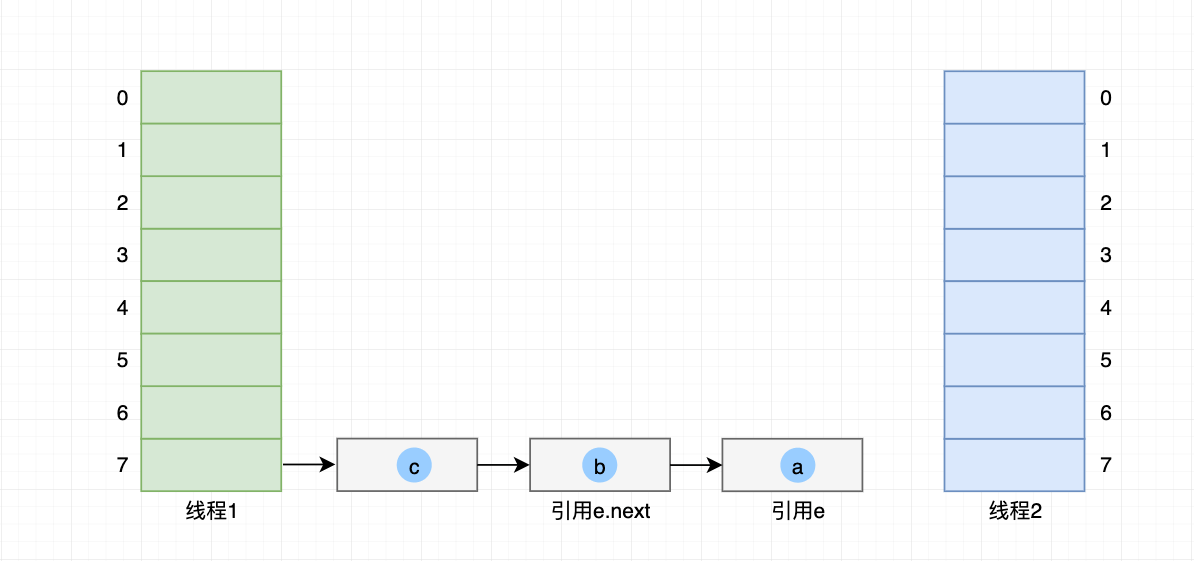
线程2 恢复 void transfer(Entry[] newTable) 的操作:
-
把 引用e 所指定的 元素a 头插法放入自己的 哈希桶7 内;
- 引用e 指向 元素a 下一个链表节点 元素b;
- 同理 e.next 本来指向 元素b,根据 元素b的next 又指回 元素a;
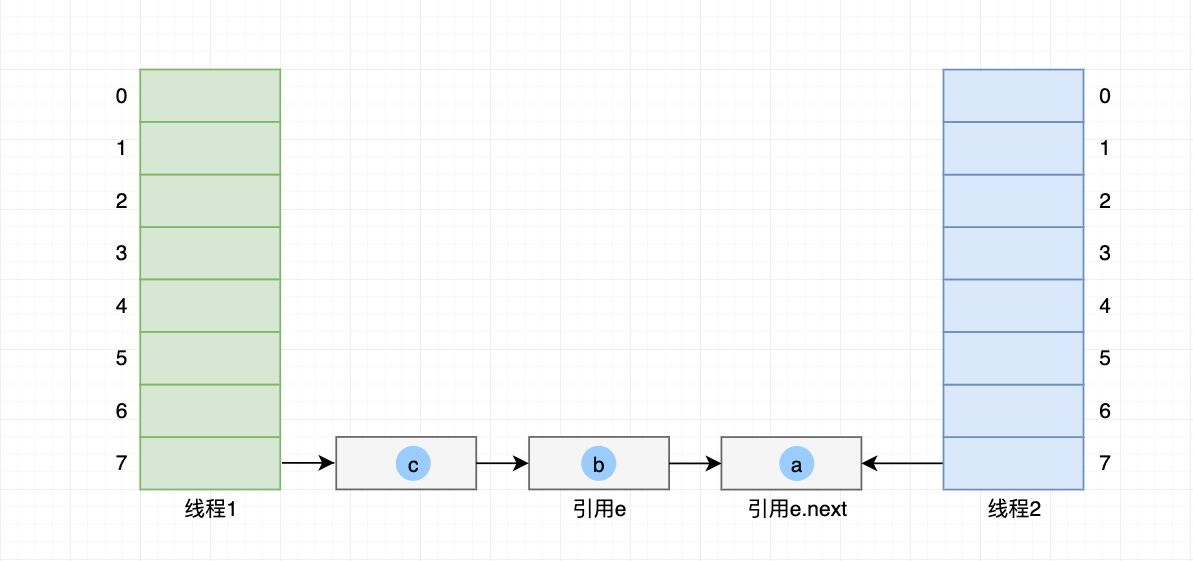
元素b 也通过头插法插入到 线程2 的 哈希桶7。顺序变成:哈希桶7->元素b->元素a
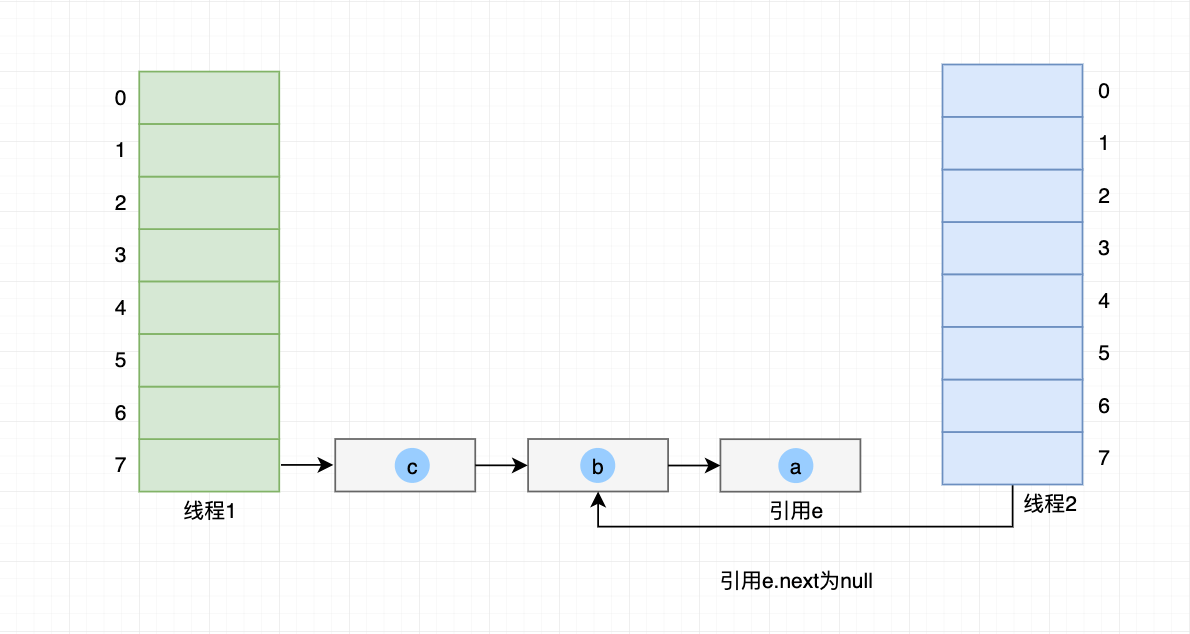
线程2 继续执行:
- 引用e 继续移动指向 元素a,因为 元素a的next 为null,所以 e.next 也为null;
- 从上图知道原来顺序是 哈希桶7->元素b->元素a;
- 元素a 头插法到 哈希桶7,顺序变为下图的 哈希桶7->元素a->元素b;
- 至此,元素a 被两次插入到 哈希桶7,导致 元素b 和 元素a 互相引用;
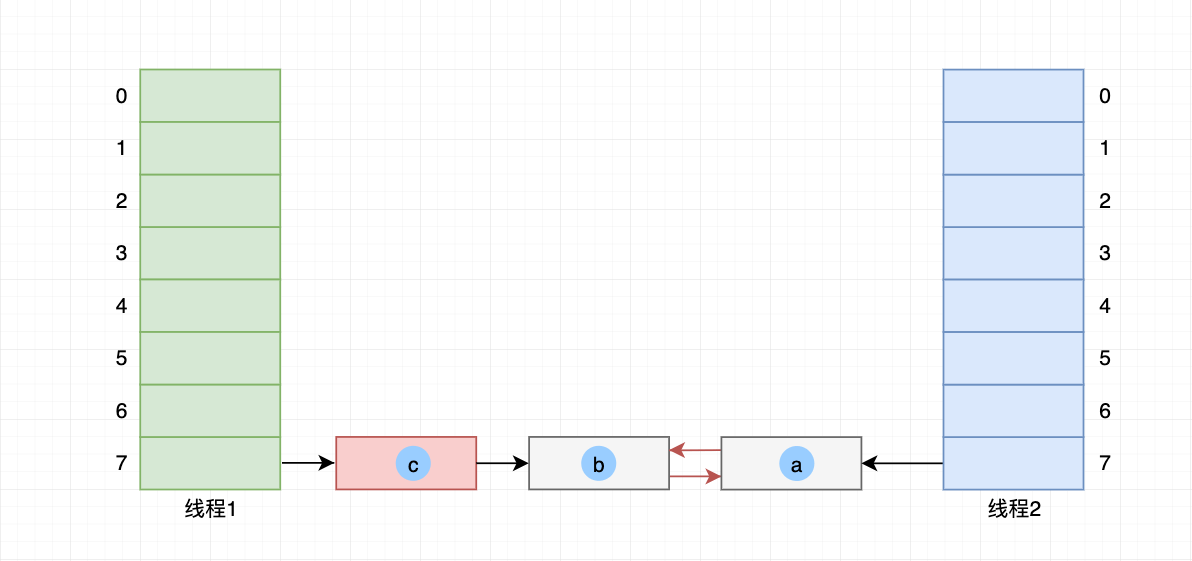
最后,如果 线程1 先把新哈希桶替换旧哈希桶,后续 线程2 又覆盖 线程1 的桶替换操作,那么 元素c 将永远不会得到访问。
当然,无论哪个线程最终完成旧哈希桶替换,只要执行 get(Key) 操作且命中到 哈希桶7,都会发生死循环。
五、参考链接
-
上一篇
Ubuntu18.04,CUDA10.0,TensorFlow-GPU安装 -
下一篇
Fix: Only fullscreen activities can request orientation